Generate Subgoal Images before Act: Unlocking the Chain-of-Thought Reasoning in Diffusion Model for Robot Manipulation with Multimodal Prompts
Abstract
Robotics agents often struggle to understand and follow the multi-modal prompts in complex manipulation scenes which are challenging to be sufficiently and accurately described by text alone. Moreover, for long-horizon manipulation tasks, the deviation from general instruction tends to accumulate if lack of intermediate guidance from high-level subgoals. For this, we consider can we generate subgoal images before act to enhance the instruction following in long-horizon manipulation with multi-modal prompts? Inspired by the great success of diffusion model in image generation tasks, we propose a novel hierarchical framework named as CoTDiffusion that incorporates diffusion model as a high-level planner to convert the general and multi-modal prompts into coherent visual subgoal plans, which further guide the low-level foundation model before action execution. We design a semantic alignment module that can anchor the progress of generated keyframes along a coherent generation chain, unlocking the chain-of-thought reasoning ability of diffusion model. Additionally, we propose bi-directional generation and frame concat mechanism to further enhance the fidelity of generated subgoal images and the accuracy of instruction following. The experiments cover various robotics manipulation scenarios including visual reasoning, visual rearrange, and visual constraints. CoTDiffusion achieves outstanding performance gain compared to the baselines without explicit subgoal generation, which proves that a subgoal image is worth a thousand words of instruction. The details and visualizations are available at https://cotdiffusion.github.io/.
Motivation Example
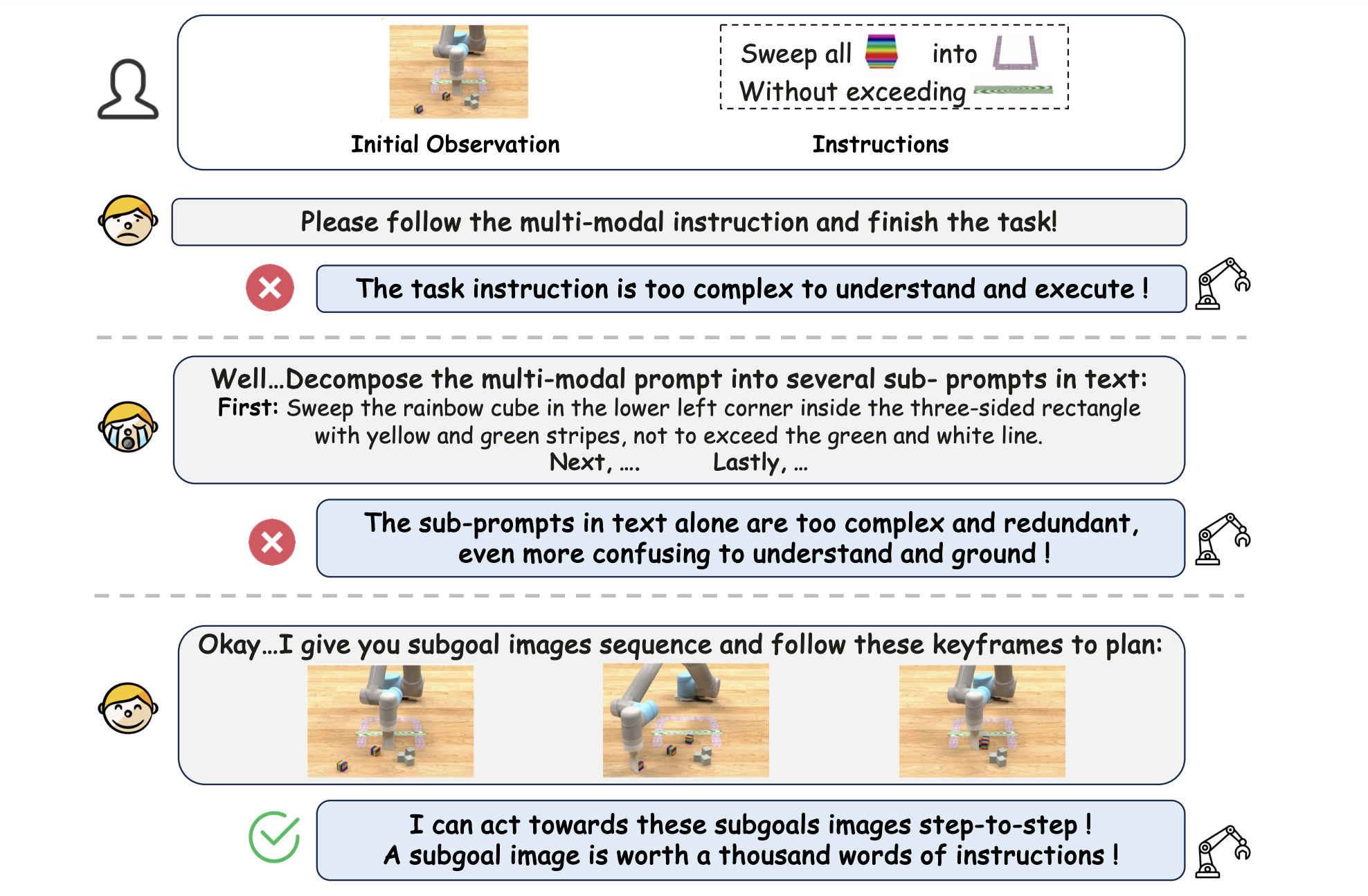
A motivation example of robotics manipulation tasks in multi-modal instructions. The subgoal images are worth a thousand words, inspiring us to propose a novel framework CoTDiffusion to generate goal images step-by-step before act.
Method
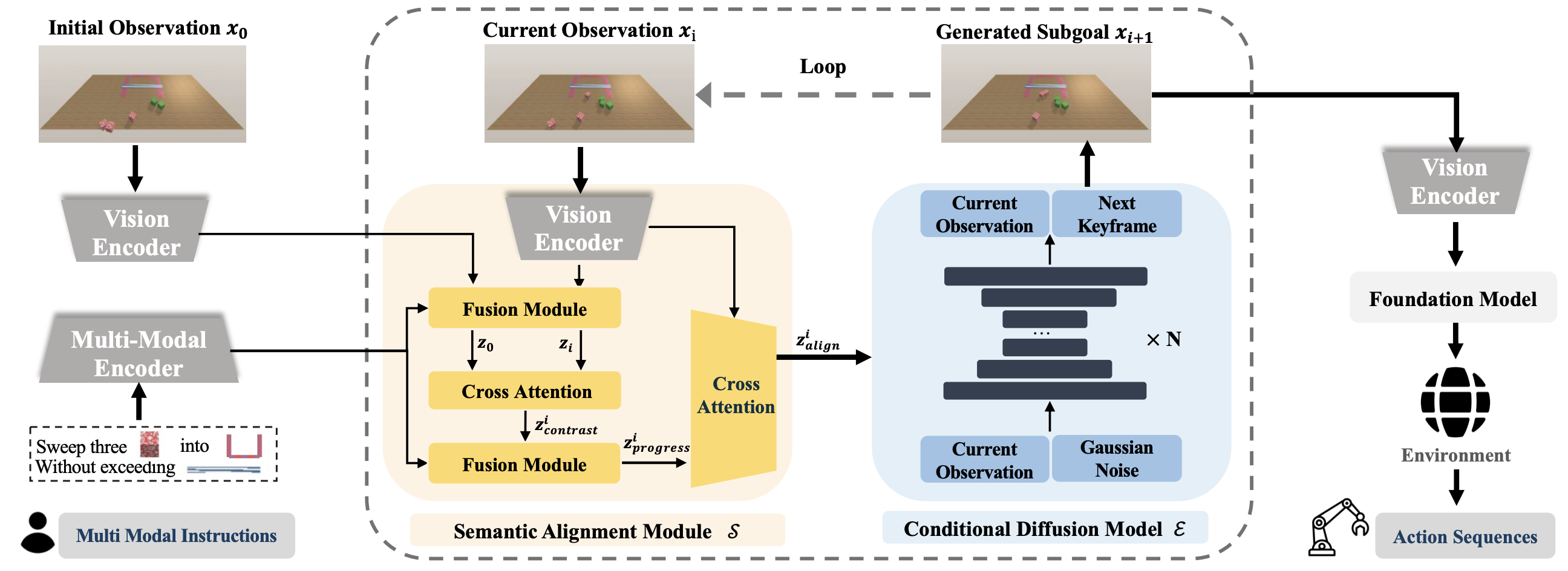
Overview of CoTDiffusion. CoTDiffusion consists of a multi-modal encoder and vision encoder V, semantic alignment module S, conditional diffusion model E, and foundation model F for action planning.
The prompt and observation tokens are combined and fed into the semantic alignment module to identify the current reasoning chain step, providing progressive guidance for the diffusion model to generate the next subgoal image.
The generated keyframes are further fed to the foundation model which predicts action sequences to achieve the imagined goal scene and this recursive process repeats in a receding horizon control loop until the task is finished.
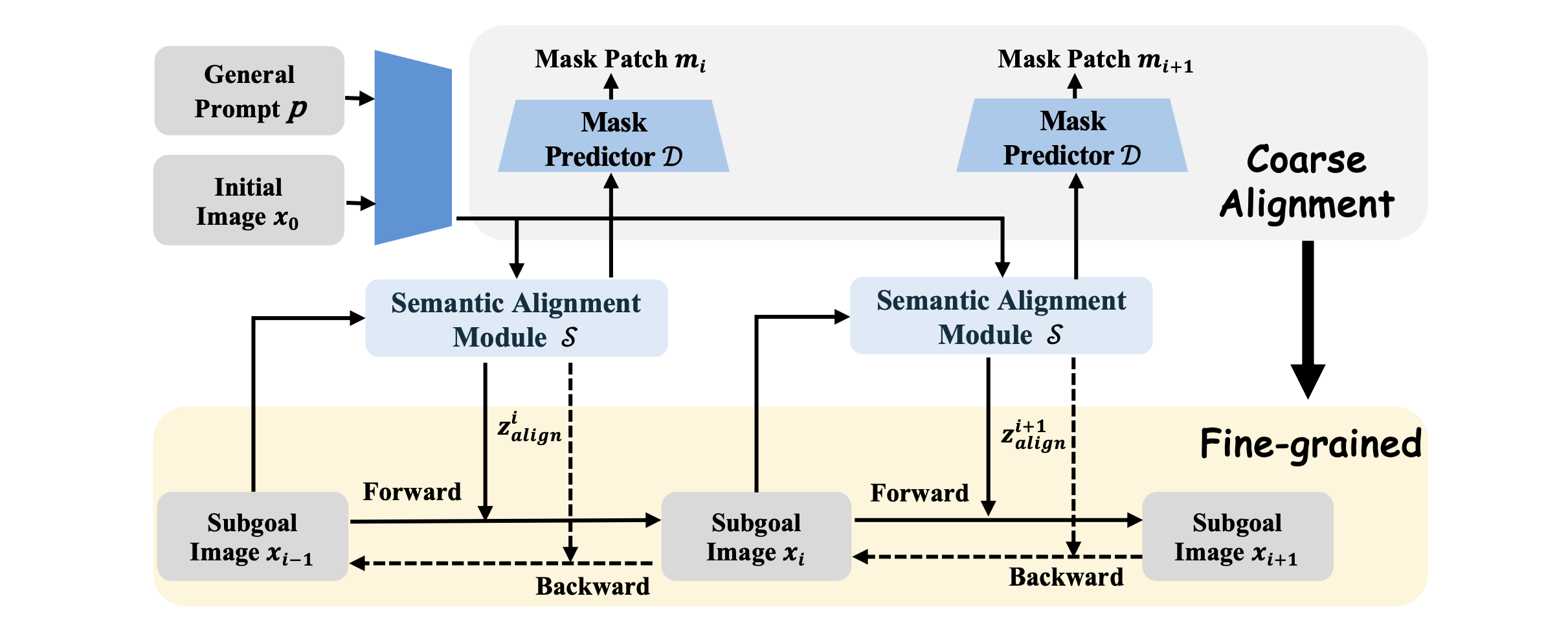
The two phases of coarse-to-fine alignment module . First, the aligned module is coarsely pre-trained to predict residual mask patches between subgoal images for aligning spatial semantics, focusing on salient differences rather than pixel details in textures or colors.
The semantic alignment module is then integrated into the diffusion model for step-wise image generation with fine-grained pixel reconstruction. Additionally, bi-directional generation and frame concatenation mechanism further enhance subgoal image fidelity and instruction following.
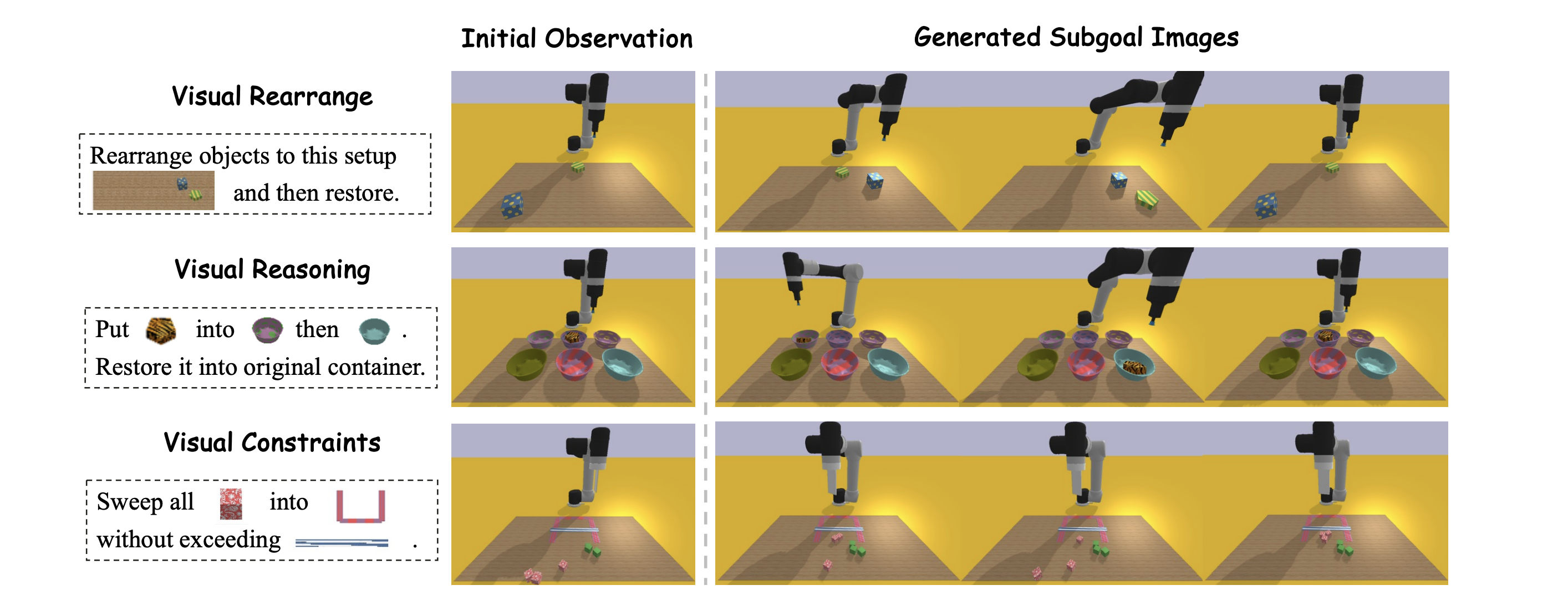
The visualization of CoTDiffusion in three typical long-horizon tasks with multi-modal prompts in VIMA-BENCH.
Quantitative Results
Main Evaluation on Success Rate
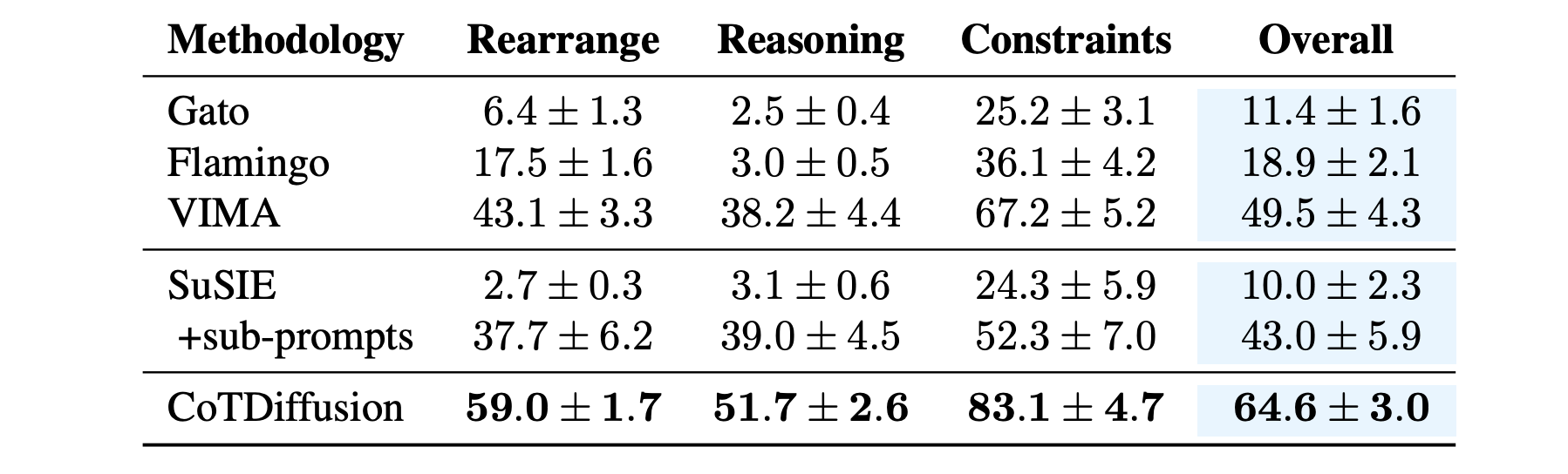
The baselines can be divided into two kinds of planners, including abstract planner and visual planner.
Abstract planner like Gato, Flamingo and VIMA directly map general prompts to subsequent actions in an end-to-end manner. Gato and Flamingo gets low success rates on long-horizon tasks without explicit subgoal generation to correct the accumulative deviation errors from the instructions.
In contrast, visual planner like SuSIE and CoTDiffusion can generate intermediate goal images to guide the action planning, which can enhance instruction following for long-horizon tasks via visual planning.
Robustness to Insufficient Perception
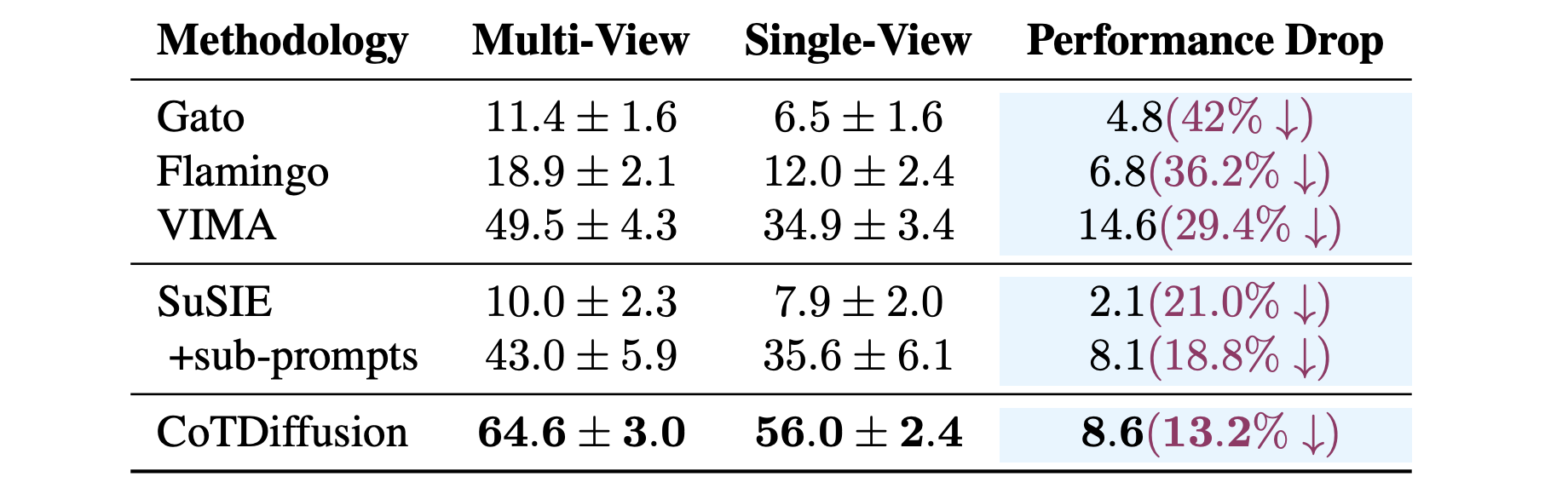
The experiments demonstrate that CoTDiffusion enjoys better robustness to restricted perception than abstract planners, highlighting the benefits of hierarchical framework decoupled visual planning and action planning. Accurate and grounded subgoal images generated in visual planners provide supplemental visual context, which can partly compensate for the insufficient perception to aid robustness under single-view.
The requirements for the low-level action planner are reduced to basic single-object manipulation primitives in short horizon by providing coherent subgoal images as visual landmarks, with less reliance on rich visual perceptions.
Fidelity of Image Generation
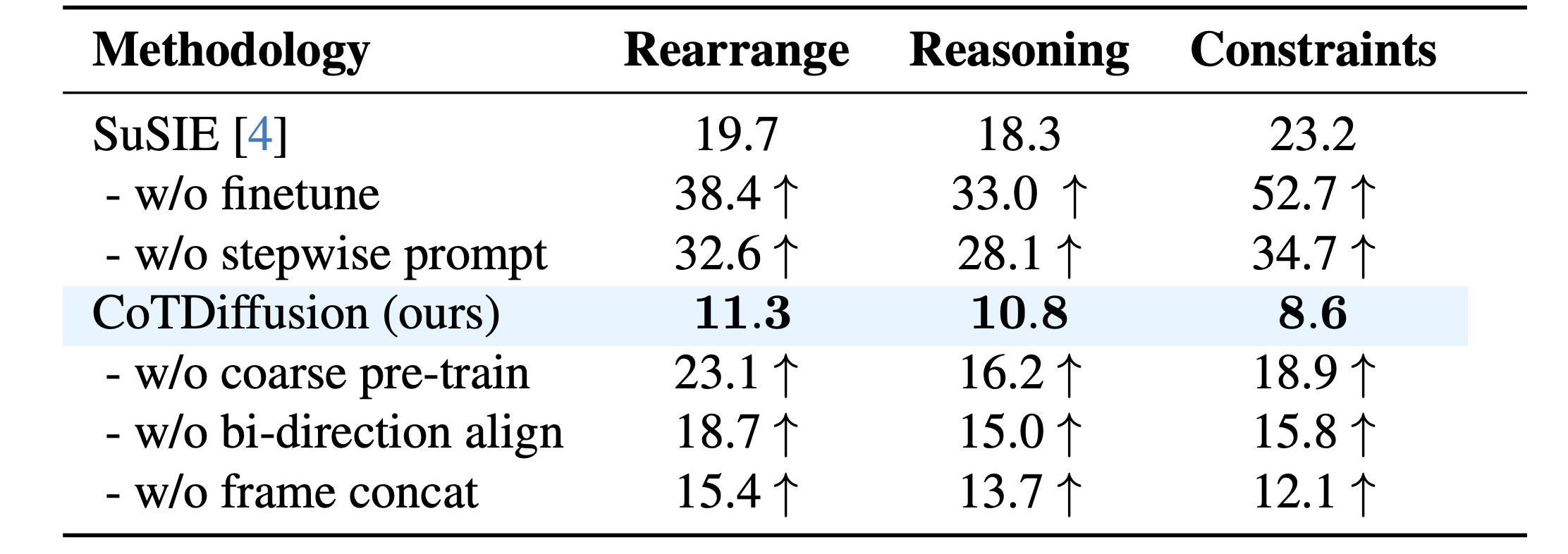
With step-wise sub-prompts decomposed in advance, the performance of SuSIE gets largely raised but still underperforms CoTDiffusion, which has no need to explicitly decompose the general prompts and can generate subgoal images in an implicit chain-of-thought manner. The coarse-to-fine semantic alignment training training allows developing spatial reasoning prior to synthesis.
Frame concatenation further guides coherent denoising by providing rich context information as visual priors to ground the current observation and enhance the fidelity of generation.
Accuracy of Instruction Following
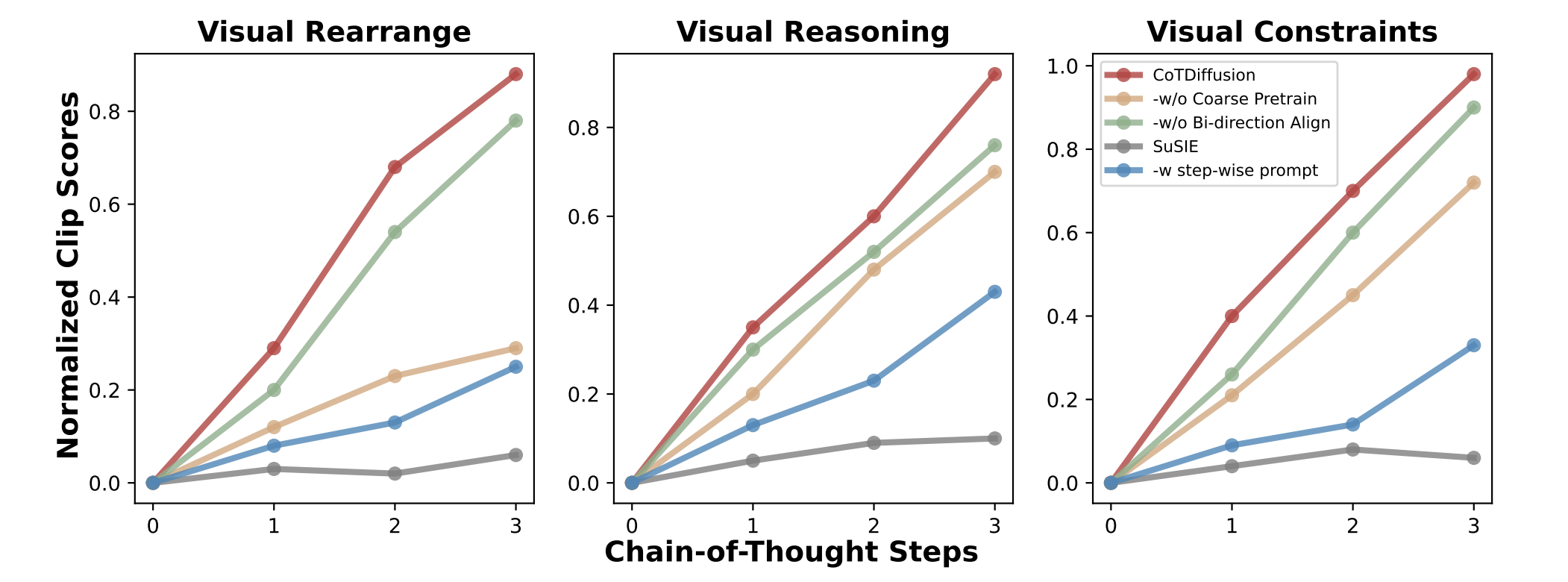
We evaluate instruction following accuracy via CLIP similarity between generated keyframes and general prompts, normalized by the CLIP score between ground truth ultimate goal image and prompts. Without chain-of-thought reasoning abilities, SuSIE struggles to follow instructions when given general multi-modal prompts, let alone generate subgoal images with smooth progressions. The coarse alignment pretraining and bi-directional generation can assist CoTDiffusion in tracking the progress of generated keyframes throughout the entire chain and generate sequenced keyframes incrementally advancing prompt instructions.
Generalization across Tasks
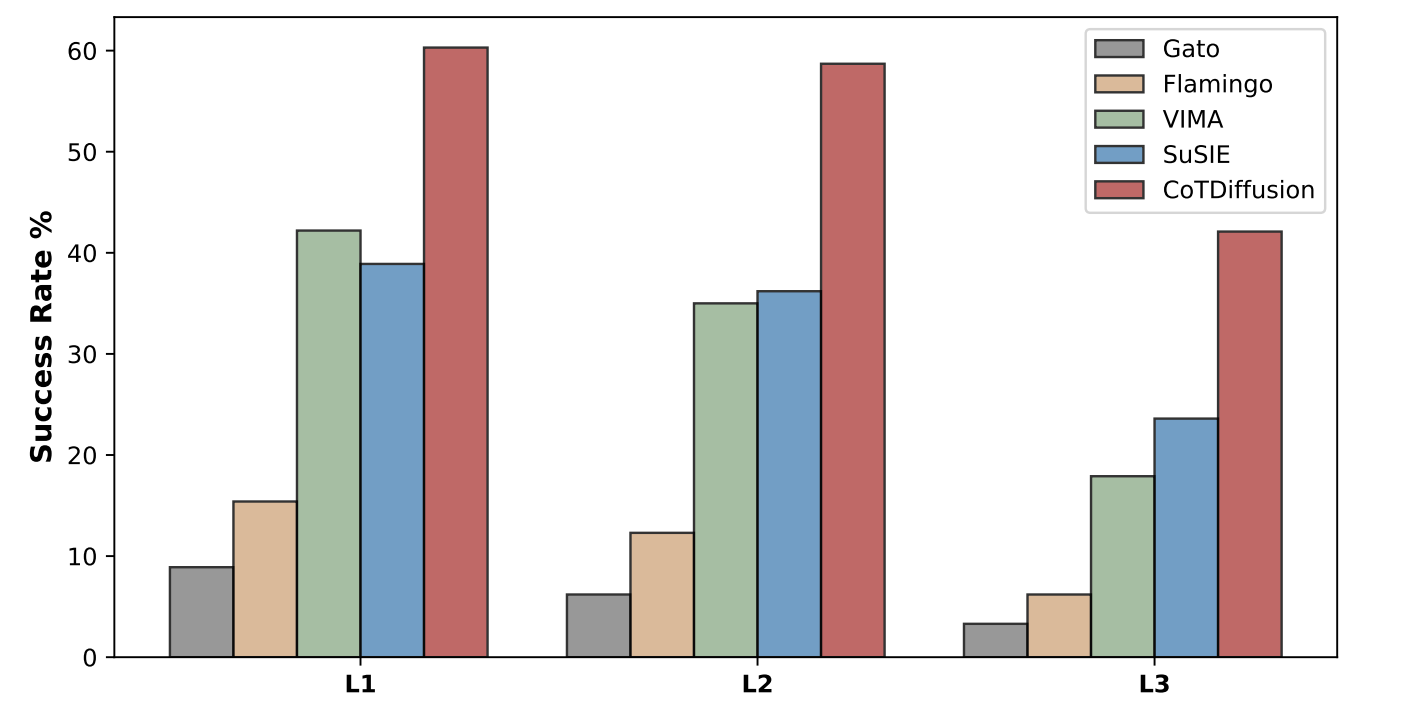
We evaluate the generalization ability in three levels with increasing difficulty: placement generalization which randomizes the novel placement of objects (L1), object generalization which provides the objects with novel attributes (L2), and task combinatorial generalization which complexes the prompts with extra novel instruction (L3).
When CoTDiffusion visualizes novel concepts into goal images, the foundation model can still accomplish the stack by simply achieving the provided subgoal, with no need to inherently understand novel skills like stack.
Ablation Studies of Horizon Length
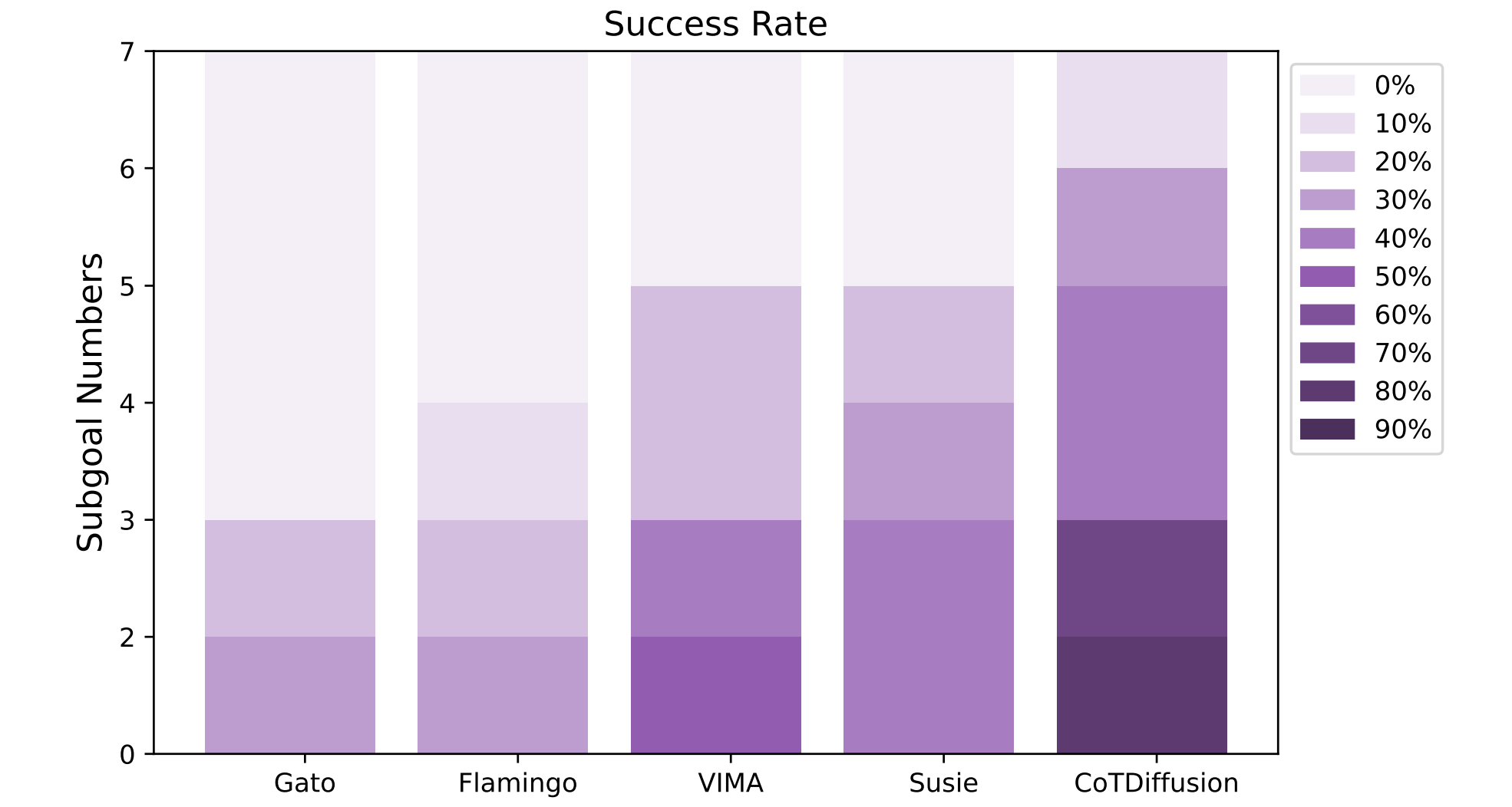
We conduct an additional experiment by increasing the number of objects and the corresponding manipulation steps to evaluate the success rate of different methods on more complex and longer-horizon manipulation tasks. The results demonstrate that CoTDiffusion enjoys better robustness for longer horizons compared to abstract planners, with the benefit from the explicit visual subgoals providing improved guidance for following complex instructions.
Ablation Studies of Model Capacity
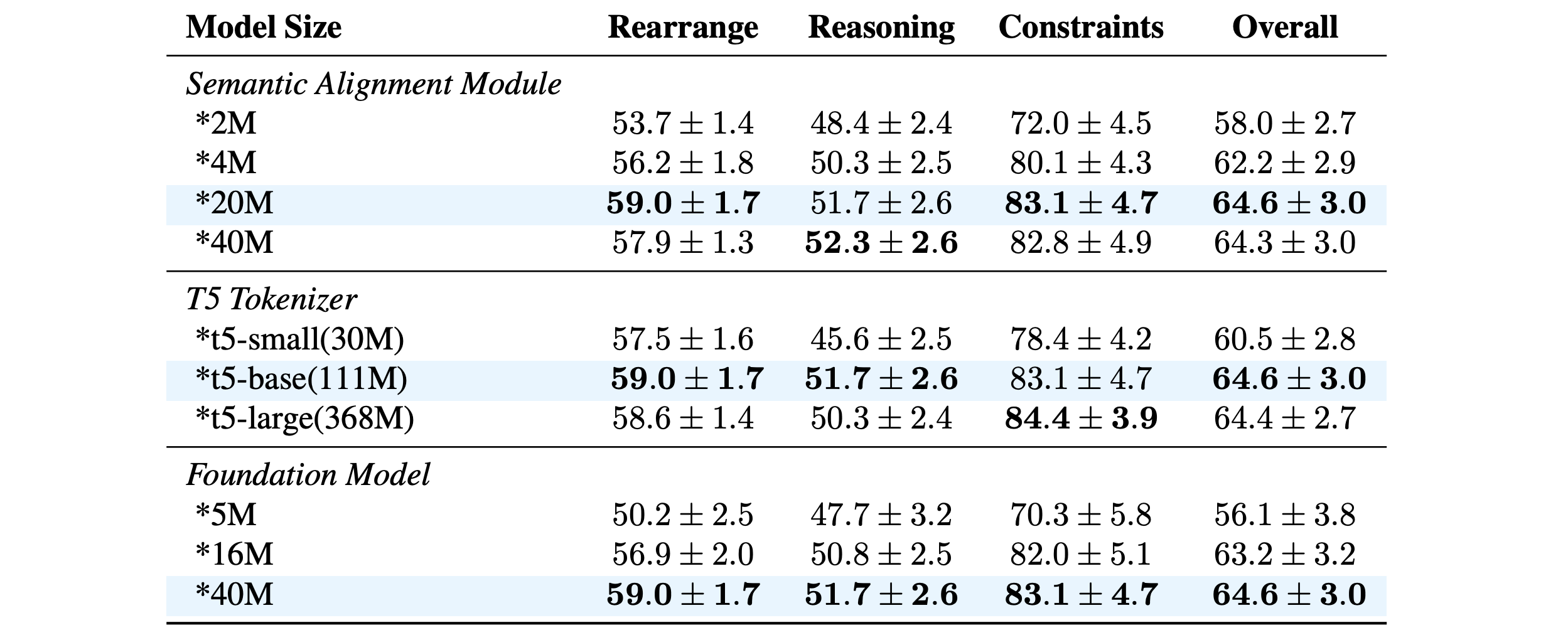
We conduct additional ablation experiments on the model capacity of some key components, including the semantic alignment module, T5 tokenizer, and low-level foundation model. Based on the experiments, we chose T5-base, a 20M semantic alignment module, and a 40M foundation model as our final model configuration.
Qualitative Examples
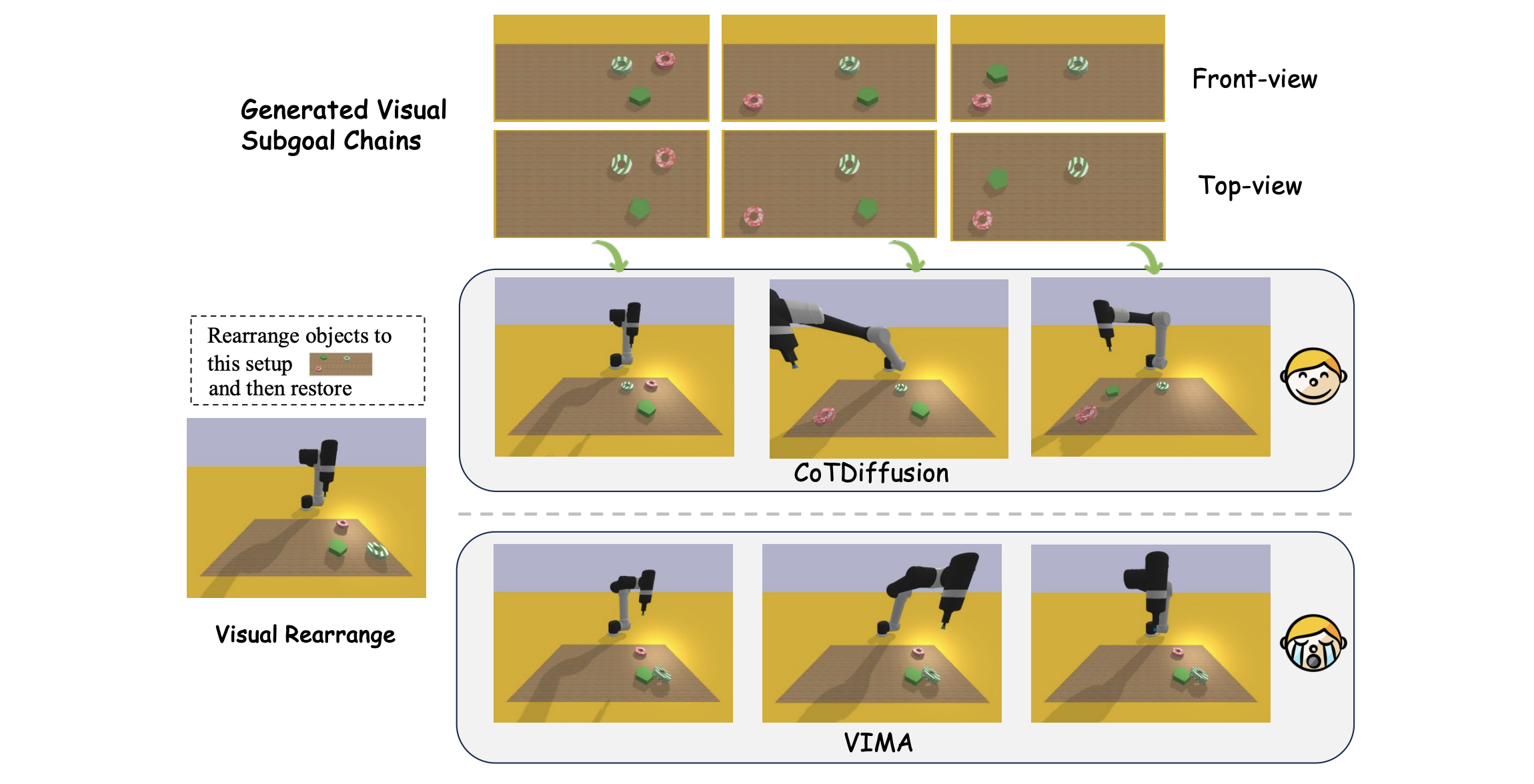
Visualization of CoTDiffusion and VIMA in visual rearrange long-horizon tasks with multi-modal prompts.
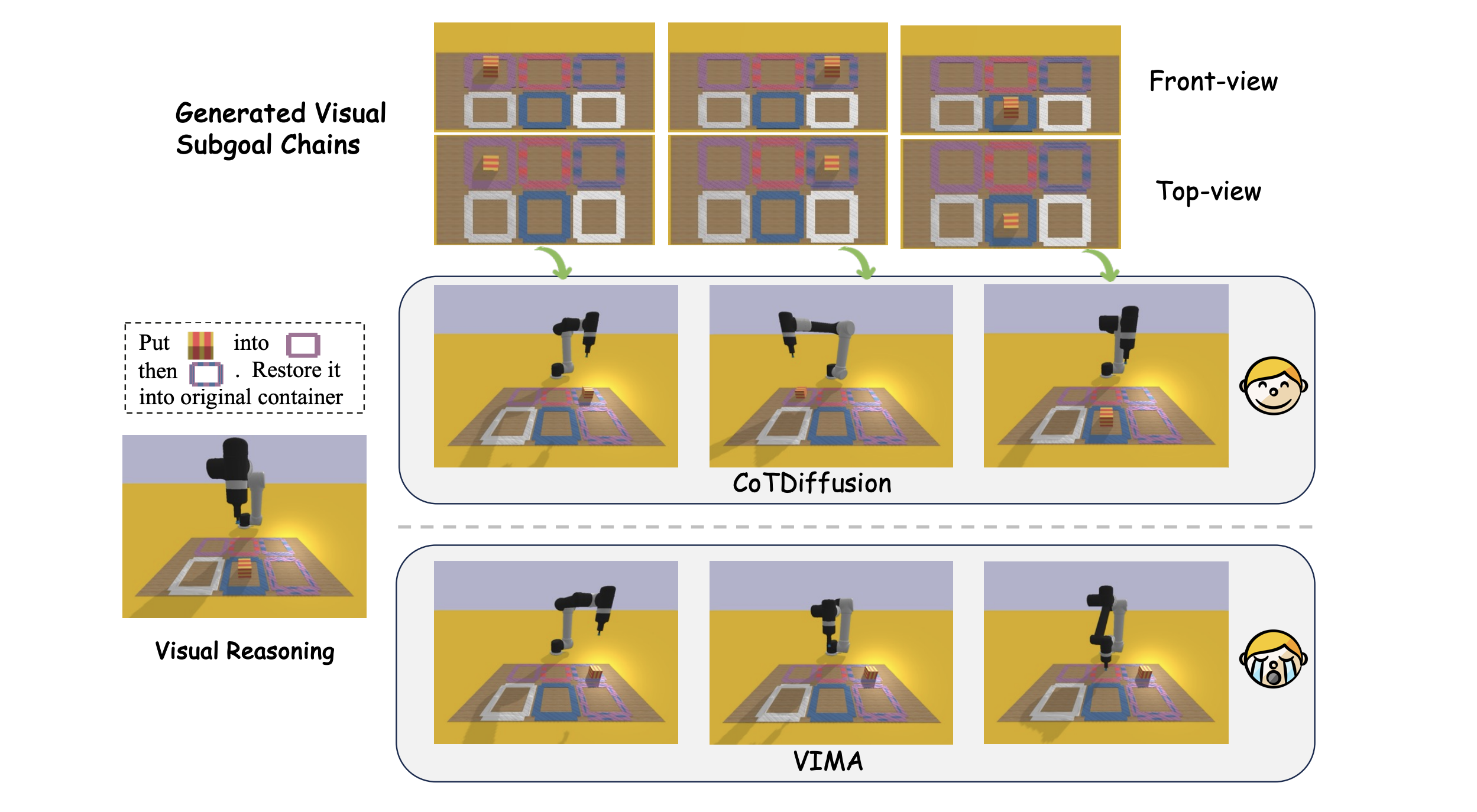
Visualization of CoTDiffusion and VIMA in visual reasoning long-horizon tasks with multi-modal prompts.
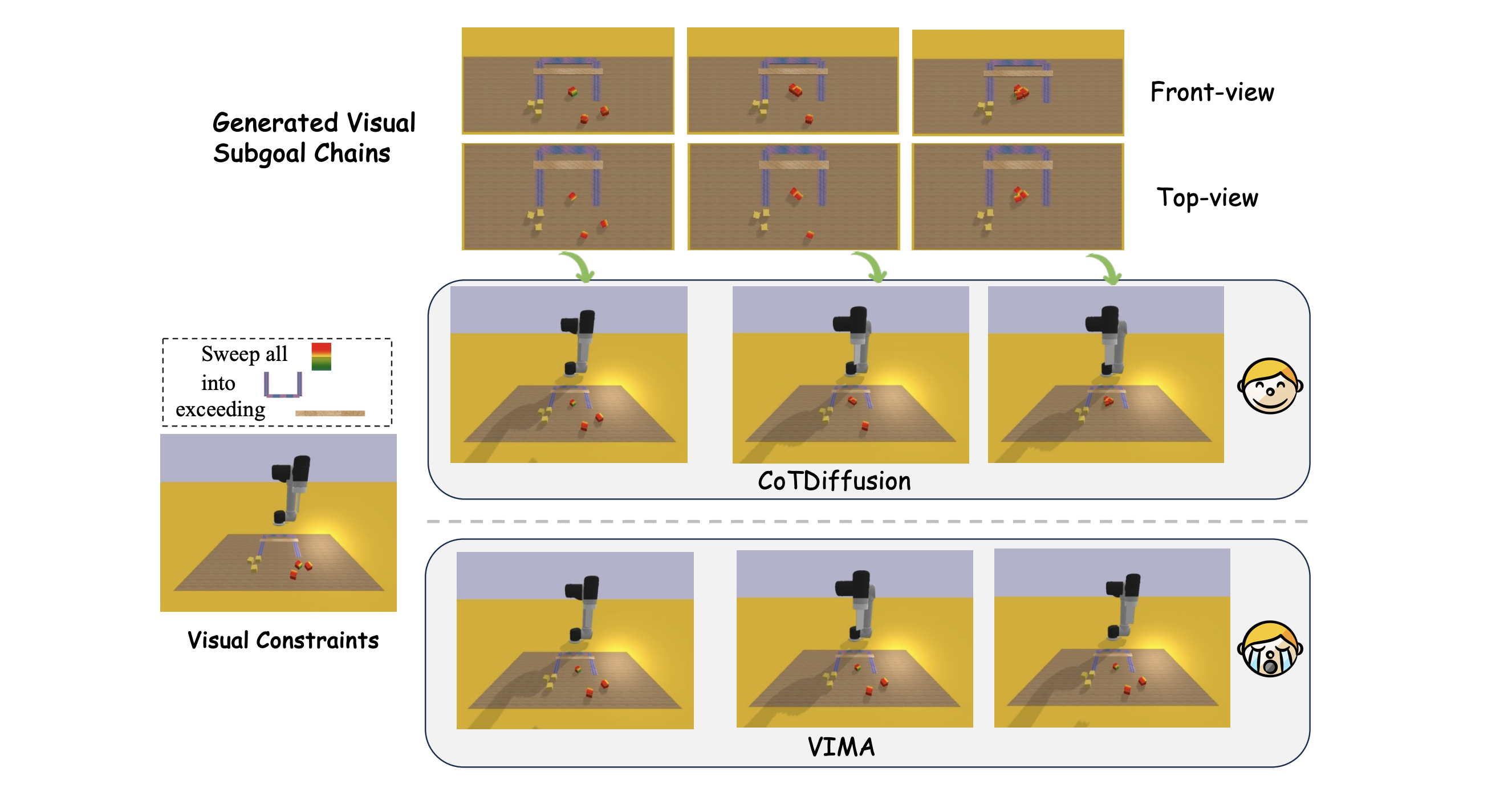
Visualization of CoTDiffusion and VIMA in visual constraints long-horizon tasks with multi-modal prompts.
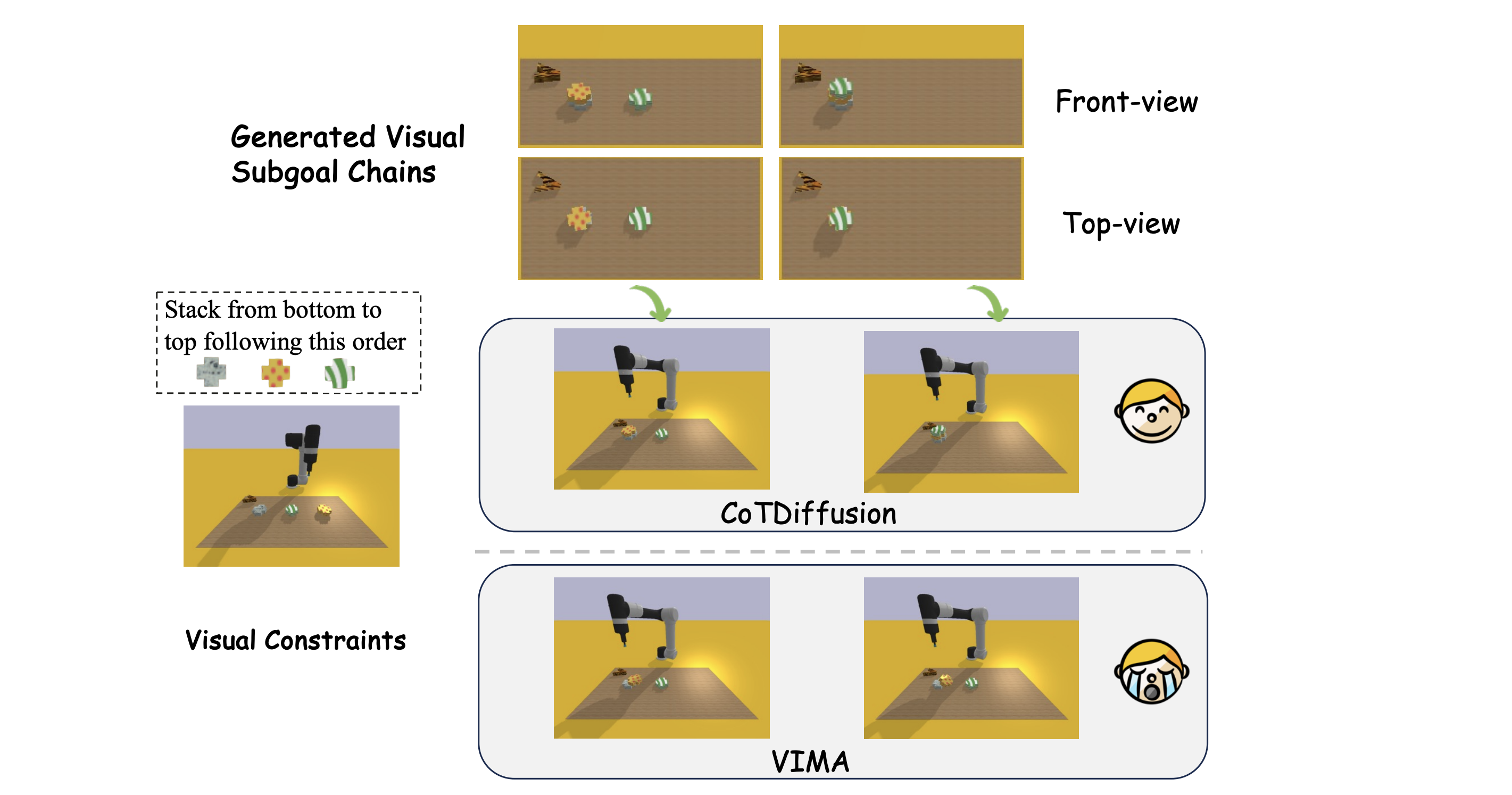
Visualization of CoTDiffusion and VIMA in novel generation tasks with novel concept with `stack'.
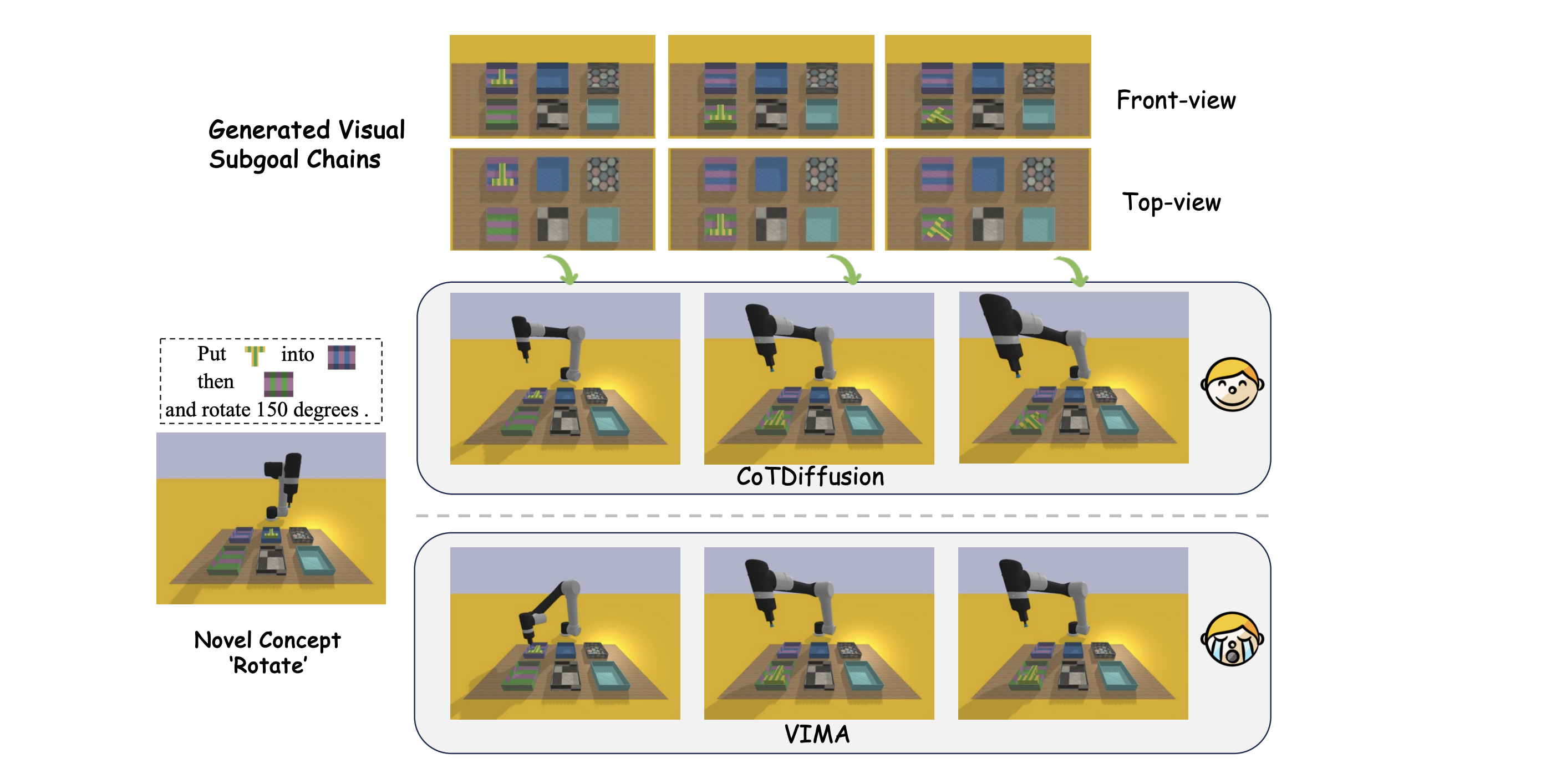
Visualization of CoTDiffusion and VIMA in novel generation tasks with novel concept with `rotate'.
Pseudocodes of CoTDiffusion

Conclusion
We presented CoTDiffusion, a hierarchical framework that integrates diffusion model as high-level module to translate the general multi-modal prompts into coherent subgoal images, serves as the visual milestones to anchor the low-level foundation model to plan action sequences, termed as generate subgoal images before act. With the coarse-to-fine training for semantic alignment module, CoTDiffusion can identify the progress of generated subgoals images along reasoning chains, unlocking the chain-of-thought reasoning capabilities of diffusion model for long-horizon manipulation tasks. The experiments cover various long-horizon manipulation scenarios in VIMA-BENCH, and CoTDiffusion shows the strong instruction following and outstanding performance gain compared to existed methods without visual planning. Incorporating commonsense knowledge from pre-trained MLLM like GPT-4V provides an avenue for more generalizable and promising reasoning in CoTDiffusion, which leaves as our future work. .